現代無伺服器和邊緣執行時使得部署快速、可擴充套件的應用程式比以往任何時候都更容易。但隨著應用程式變得更加分散式,效能問題往往從程式碼轉移到基礎設施。
本文探討了全球分散式應用程式中常見的後端瓶頸:長時間的資料庫往返、連線攪動、冷啟動和低效查詢。它還介紹了連線池、快取、區域感知部署和更智慧監控等實用解決方案,以確保您的應用程式無論使用者身在何處都能保持快速。

邊緣和無伺服器的真正含義
在我們深入探討之前,先快速定義一下背景。
無伺服器意味著您編寫一個函式,部署它,然後您的雲提供商按需執行它。您無需考慮基礎設施。它會自動進行擴充套件和縮減。
邊緣意味著這些函式在靠近使用者的地方執行。您的程式碼可能為日本使用者在東京執行,為德國使用者在法蘭克福執行。這減少了物理距離,從而降低了延遲。
這對於前端響應能力和輕量級API來說非常棒——但它在幕後也引入了新的挑戰。
為什麼無狀態函式會使事情複雜化
其中一個挑戰是無伺服器和邊緣函式是無狀態的。它們在請求之間不保留狀態。因此,每次請求到來時,可能會啟動一個新例項,並且沒有與資料庫的持久連線。
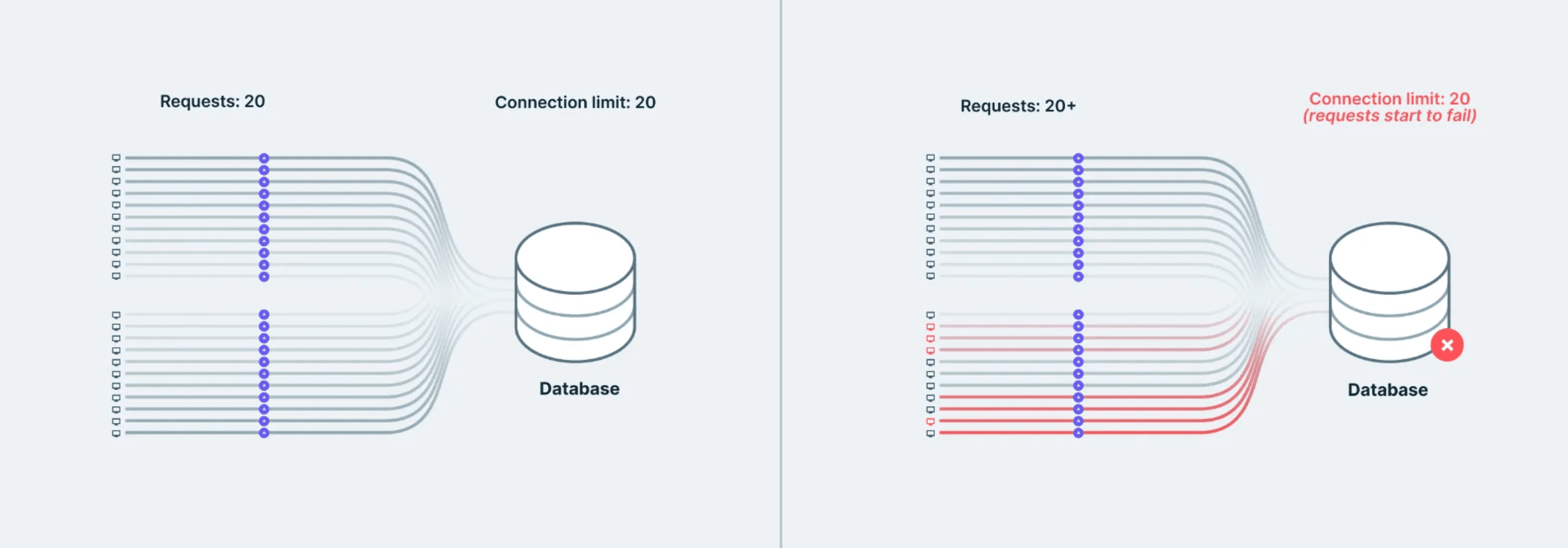
這導致了一個稱為連線攪動的問題:數以百計的新連線被快速開啟和關閉。
如果1000個使用者同時訪問您的函式,那麼在短時間內會產生1000個數據庫連線。大多數資料庫都不是為此而設計的。您會達到連線限制,您的資料庫開始限流,一切都變得緩慢。
冷啟動加劇了這個問題。如果一個函式最近沒有被使用,第一個請求會因為執行時啟動並建立新連線而變慢。
使用連線池
解決方案?連線池。
連線池允許多個函式呼叫共享一組小的、持久的連線。它充當您資料庫前的一個佇列。每個函式不再開啟新連線,而是從池中獲取一個連線。
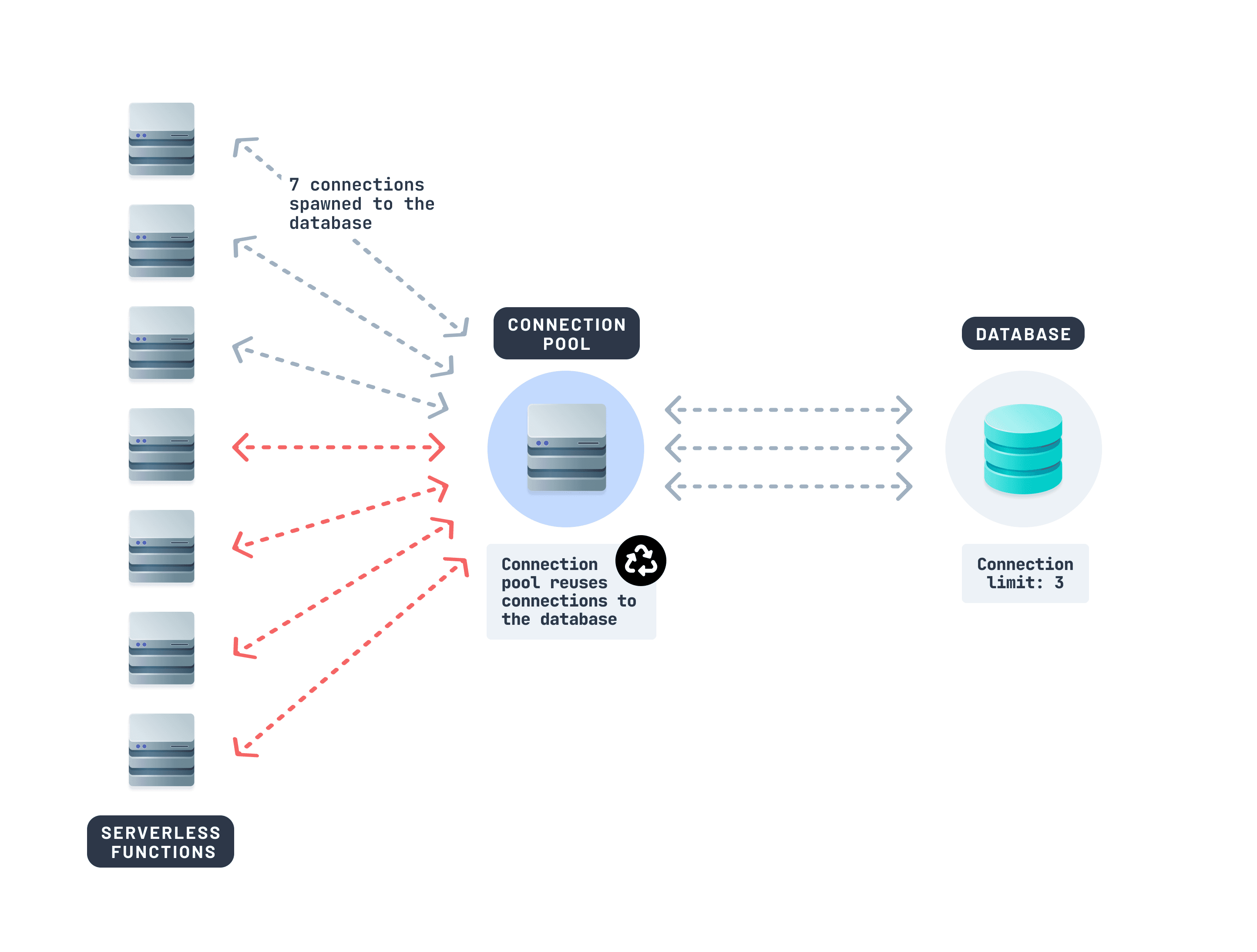
如果您使用的是像Prisma Postgres這樣的資料庫,連線池會在幕後自動處理——跨函式自動進行連線池和查詢最佳化。其他工具,如PgBouncer或Supavisor(來自Supabase),也可能很有用。
單獨為您的資料庫使用連線池器就可以穩定高流量邊緣環境中的效能。
至此,我們已經解決了如何管理過多連線的問題。但導致邊緣效能緩慢的幕後還有另一個隱藏的罪魁禍首。
您的邊緣應用程式不慢,是到資料庫的往返時間慢
想象一下,您將邊緣函式部署到東京。它執行速度極快——直到它呼叫弗吉尼亞州的資料庫。突然間,您的響應時間增加了500毫秒。
這不是您的程式碼問題。這是地理位置問題。
邊緣執行時速度很快,但如果您的函式必須跨洋查詢資料庫,每個請求都會增加數百毫秒的往返延遲。將其乘以多個查詢,使用者體驗就會受到影響。
讓我們探索如何解決這個問題。
快取不需要即時的資料
減少不必要的資料庫呼叫的最簡單方法之一是快取不經常更改的資料。
思考一下:產品列表、網站設定或功能標誌。這些值不需要每次都重新獲取。
您可以使用以下方式快取資料庫查詢:
- 使用適當的
Cache-Control頭實現CDN級別快取 - 邊緣鍵值資料庫(如Vercel KV、Cloudflare Workers KV)
- 在“熱”無伺服器函式內部進行記憶體快取
- 使用具有內建快取的資料庫提供商,例如Prisma Postgres
快取可以減輕資料庫的負載,並顯著縮短重複請求的往返時間。
將您的函式和資料庫共置
另一種加速API的方法是將您的程式碼和資料庫執行在同一個區域。
假設您的資料庫託管在us-east-1(弗吉尼亞州)。但您的邊緣函式是從東京呼叫的。如果函式執行在靠近使用者的地方(例如在ap-northeast-1),但資料庫位於太平洋彼岸的美國,那麼每個查詢都必須進行長途網路往返——多次。
延遲就是在這裡迅速累積的。
函式可能看起來像這樣:
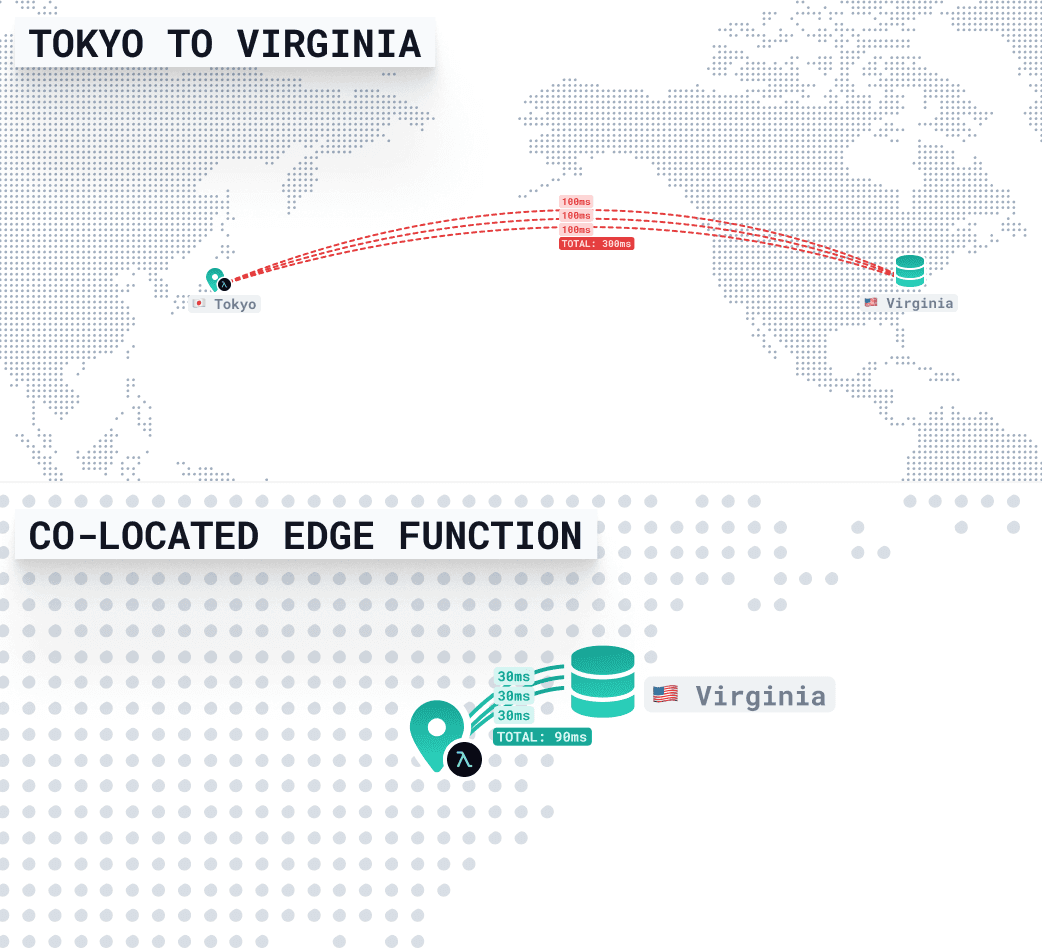
如果函式靠近使用者(在東京),但遠離資料庫(在弗吉尼亞州),每個資料庫查詢都需要時間——由於跨太平洋網路延遲、TLS握手和DNS解析,每次往返大約需要300毫秒。
此處理程式按順序執行三個依賴查詢
- 3個查詢 × 300毫秒 = 約900毫秒總延遲
所以,即使您的函式還沒有做任何實際工作,也幾乎有一秒鐘的時間只是在等待資料。
現在將它們共置
透過將函式執行在與資料庫相同的區域(弗吉尼亞州),這些查詢不再需要跨越海洋。它們保持在本地——通常每個查詢在10-30毫秒內完成。
這意味著即使請求來自東京,整個響應也能在90毫秒內返回。使用者仍然會因為距離產生一些延遲,但您的後端保持快速和一致。
區域鎖定使其可行
像Vercel、AWS Lambda等平臺允許您將函式鎖定到特定區域——在本例中是us-east-1。
對於Vercel中的邊緣部署,region配置可以使您鎖定一個區域
這種設定在以下情況最為理想:
- 您按順序執行多個查詢
- 您想避免編寫複雜的客戶端快取
- 您關心穩定、低延遲的API
與將後端分佈在全球各地不同,將計算與資料共置可以避免數百毫秒的開銷——只需一行配置。
何時考慮多區域資料庫
如果您的大多數使用者都在讀取資料並且分佈在全球各地,多區域資料庫會有所幫助。
這會將您的資料複製到不同區域,因此歐洲、亞洲或澳大利亞的使用者可以從離他們最近的副本讀取資料。這可以改善延遲並減少單個數據庫節點的負載。
像AWS這樣的雲提供商提供了多區域功能,如DynamoDB Global Tables和Aurora Global,但像CockroachDB這樣專門構建的資料庫也使得跨區域複製資料以獲得更好效能變得容易。
分散式資料庫在以下情況是很好的選擇:
- 讀取量遠超寫入量
- 輕微的資料不一致(最終一致性)可接受
- 您想減少全球往返次數
但如果出現以下情況則暫緩使用:
- 您的應用程式需要嚴格一致性(例如金融交易)
- 您在多個區域有頻繁的寫入操作
- 您需要精確控制版本衝突
關注您的查詢
即使您使用了快取並進行了共置,糟糕的查詢仍然會成為效能瓶頸。
儘早設定監控以跟蹤百分位延遲
- p50 = 中位數查詢時間
- p75 = 較慢的查詢,通常在輕負載下
- p99 = 最壞情況下的查詢,效能問題通常隱藏在此處
例如,p50為30毫秒很棒——但如果您的p99為700毫秒,一些使用者仍然會遇到痛苦的延遲。
在識別效能瓶頸時,還要注意:
- N+1查詢模式
- 過濾欄位上缺少索引
- 過度獲取巢狀資料
僅僅最佳化幾個繁重的查詢就能將您的總體延遲減少一半。像Prisma Optimize這樣的工具透過識別邊緣和無伺服器函式中最慢的查詢、查明根本原因並提出可行的修復建議,從而使這一過程變得更容易。

快速回顧
以下是問題及解決方案的快速一覽。
總結
部署到邊緣很容易。但要讓您的應用程式感覺快速——尤其是在全球範圍內——則需要更多的思考。
好訊息是?您無需重建您的技術棧。一些小的改變——快取、共置、連線池和監控——就能帶來巨大的不同。
下次當您的邊緣函式開始感覺緩慢時,很少是計算問題。十有八九,是您的資料庫問題。這通常是速度下降的起點,也是速度提升的關鍵所在。
讓我們繼續交流
如果這篇文章對您有所幫助,我們很樂意聽取您的反饋。在X上標記我們並分享您正在構建的內容。或者如果您想聊天、解決問題或深入探討資料庫和效能,可以加入我們的Discord。
我們還會定期在YouTube上釋出深度影片。如果您對此感興趣,請點選訂閱。更多示例、更多效能技巧,也許還有一些驚喜釋出。我們到時見。
不要錯過下一篇文章!
訂閱Prisma新聞郵件