當多個團隊共享一個數據庫時,問題就會出現。遷移衝突、查詢變得臃腫,或者所有權變得模糊不清。
本文將詳細闡述大型團隊如何構建有彈性的資料工作流程——無論是使用SQL、ORM還是兩者結合——同時保持速度和自主性。我們將探討實際模式,如“擴充套件-收縮”模式、Schema CI、查詢約定以及何時使用原生SQL。
如果你正在擴展團隊和資料庫,這篇文章正是為你準備的。

為什麼資料工作流程在規模化時會崩潰
隨著團隊的壯大,他們常常在共享資料庫環境中發生衝突。結果呢?草率的遷移、意外的表更改,以及沒有人真正清楚誰擁有什麼。
當所有權模糊時,即使是善意的更改也可能導致系統崩潰。這在沒有明確定義資料庫協議的快速發展的產品團隊中尤為常見。
一些常見的故障發生在以下情況:
- 一個團隊釋出了一個遷移,刪除了另一個團隊仍然需要的列
- 表中充斥著服務於相互衝突目的的欄位
- 單一的Schema檔案有五個所有者,卻無人負責
有時,規模化更多地關乎清晰度,而非技術本身。
選擇一個工作流程,並使其簡單乏味
允許團隊以多種方式管理同一任務可能看起來很靈活——但這往往導致不一致和混亂。一個單一、簡單乏味的工作流程可以減少思維負擔,促進更順暢的協作。
團隊管理Schema變更的常見方法有三種
提示:DDL代表資料定義語言(Data Definition Language)——定義資料庫結構的SQL語句,如
CREATE、ALTER或DROP。
在所有團隊中堅持一種方法。沒有規範地混用風格會使你的工作流程更難除錯,幾乎無法擴充套件。
將Schema視為應用程式程式碼
你會不經過拉取請求(pull request)就釋出應用程式程式碼嗎?可能不會。資料庫Schema也應受到同樣嚴格的審查。
務必遵循以下實踐:
- 在Git中對每個Schema變更進行版本控制
- 透過拉取請求審查Schema變更
- 使用Prisma Migrate、Atlas或Liquibase等差異工具,在Schema變更上線前將其視覺化
這有助於提高透明度,及早發現錯誤,並建立每次演進的歷史記錄。
使用“擴充套件-收縮”模式
大型Schema變更無需承擔風險。“擴充套件-收縮”模式將變更分解為非破壞性步驟,從而最大限度地減少停機時間。
- 擴充套件:新增新欄位、表或結構
- 遷移:回填並更新任何引用或依賴
- 收縮:僅在一切安全後才移除或重新命名舊部件
這可以避免破壞生產環境,支援滾動部署,並幫助團隊即使在複雜變更的情況下也能保持正常執行時間。

無論你使用原生SQL、Prisma、Rails還是任何其他系統,這都是一個可靠的模式。訪問我們的資料指南,瞭解更多關於“擴充套件-收縮”模式的資訊。
定義何時使用SQL以及何時使用ORM
SQL和ORM是互補而非競爭的工具。關鍵在於根據你的目標選擇更適合的工具:開發速度、查詢控制和長期可維護性。
在以下情況使用ORM:
- 你希望快速進行產品開發
- 你偏好可讀、可維護且型別安全的程式碼
- 你的團隊可以透過抽象化樣板程式碼和重複任務而受益
- 你希望透過不要求每位開發者都成為SQL專家來降低開發風險
在以下情況使用原生SQL:
- 你正在最佳化複雜的連線或效能關鍵路徑
- 你需要對查詢、索引或執行計劃進行細粒度控制
- 你正在構建依賴自定義邏輯的重報告內部工具
你無需只選擇一種。大多數現代應用程式會兩者結合使用:使用ORM來快速開發並保持型別安全,當效能或靈活性有要求時,則回退到原生SQL——理想情況下,將這些查詢封裝在型別化的輔助函式中以保持可維護性。
例如,Prisma ORM中的TypedSQL允許你使用帶有完整TypeScript型別的原生SQL,就在你的ORM呼叫旁邊。這讓你擁有SQL的靈活性,同時不犧牲型別安全性和可維護性。
一些流行的工具包括:
Kysley (TypeScript), Sequelize (Node.js), Django ORM (Python), Knex (SQL builder), 透過SQLX或pgx使用的原生SQL (Rust),甚至與Atlas或Liquibase等遷移工具結合的SQL指令碼。
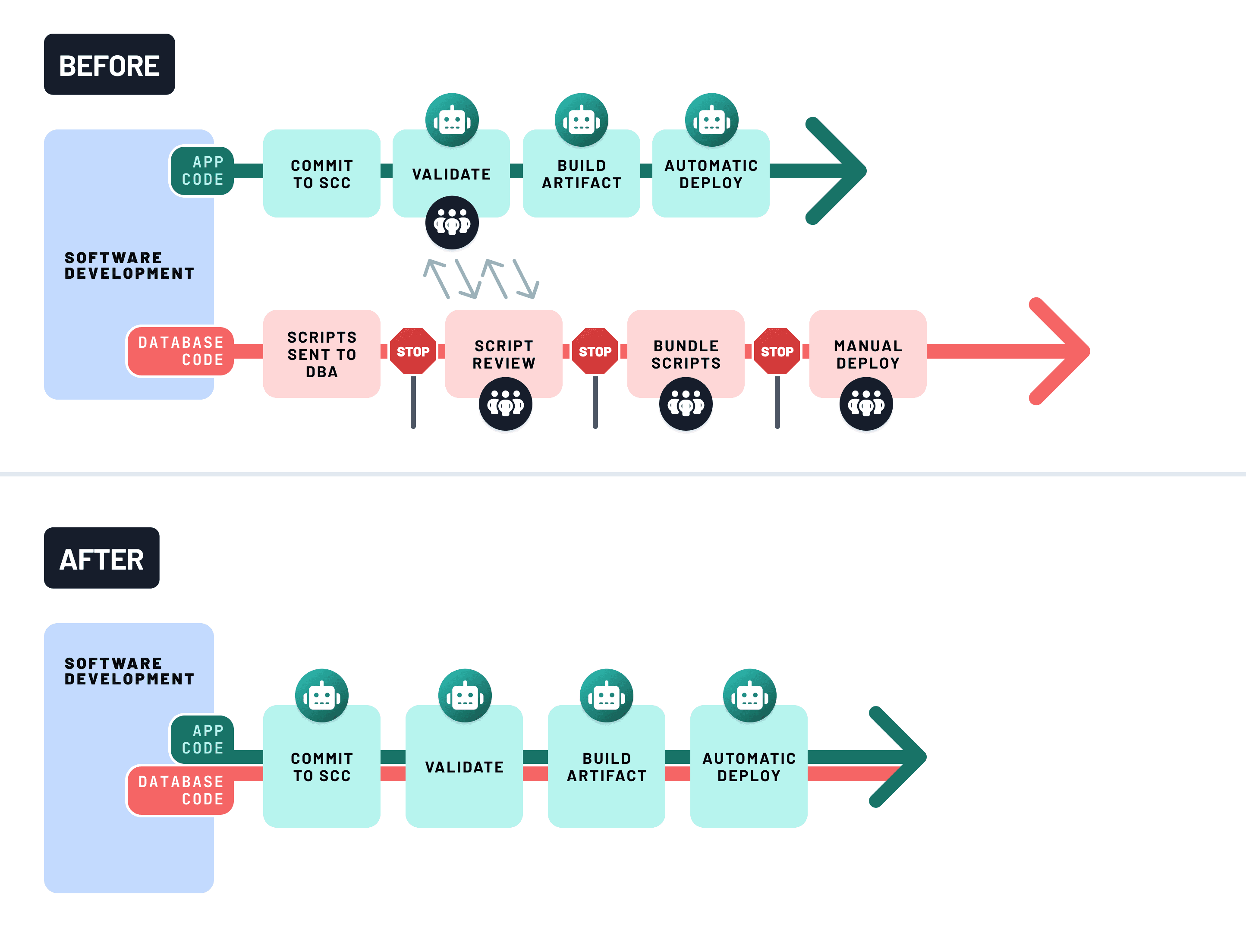
使用CI來強制執行資料庫安全
如果沒有保障措施,Schema變更可能會悄無聲息地破壞生產環境。持續整合(CI)透過在合併每個變更之前對其進行驗證來防止這種情況發生。
一個健壯的資料庫CI流水線應該:
- 預覽Schema差異使用Prisma Migrate或Atlas等工具檢測破壞性變更
- 執行整合測試對臨時或影子資料庫執行整合測試,以端到端驗證行為
- 如果檢測到破壞性操作(例如刪除列、資料丟失),則使構建失敗
使用GitHub Actions、Docker和你選擇的遷移工具來設定。例如,使用一個作業來:
- 啟動一個乾淨的PostgreSQL容器
- 應用遷移
- 執行你的測試套件
- 解析遷移計劃以查詢潛在不安全的操作
這可以在迴歸問題影響生產環境之前捕獲它們,並使Schema演進成為工作流程中可共享、可審查的一部分——而不是部署的副作用。
使用OpenAPI和Swagger定義邊界
當團隊透過API交換資料時,清晰的契約對於避免誤解和錯誤至關重要。OpenAPI是一個被廣泛採用的規範,用於以結構化格式描述RESTful API,這種格式人類和工具都能理解。
Swagger是一套圍繞OpenAPI標準構建的流行工具集。它允許團隊以最小的摩擦文件化、視覺化和測試API。
使用Swagger等工具可以幫助團隊:
- 明確定義API邊界和預期行為
- 為前端和後端自動生成型別和客戶端程式碼
- 驗證變更,及早發現破壞性更新
- 透過互動式文件瀏覽和測試API端點
- 透過模擬響應和整合型別化客戶端,幫助前端團隊更快地行動
- 透過使API自解釋和可發現來改善開發者入職體驗
這種方法在微服務架構或多個團隊依賴共享內部API時特別有效。

開發者無需依賴“部落知識”或Slack訊息來解釋API的工作方式,而是可以自信地探索、原型設計和整合——這一切都得益於準確、始終保持最新的文件。
共同定位查詢,標準化結構
分散的邏輯難以擴充套件。一致的檔案結構使你的程式碼庫更容易導航、理解和擴充套件——特別是隨著團隊的壯大。
與其將資料訪問邏輯分散在models/、utils/和services/中,不如按領域對查詢進行分組。這反映了CLEAN架構和模組化單體設計的模式,其中特性邊界而非技術層驅動結構。
為什麼這有效
- 鼓勵每個領域清晰的所有權和封裝
- 透過使查詢位置可預測來加速入職過程
- 減少跨領域關注點和不一致的抽象
- 讓你的邏輯更接近使用它的地方——更容易測試、文件化和重構
像CLEAN或基於功能的架構這樣的設計模式不僅是學術理論,它們能使協作更順暢,系統隨時間推移更具彈性。一個良好的結構會隨著你的團隊和產品的成長而擴充套件。
跨系統共享型別
前端和後端之間的型別不匹配是常見的bug來源——例如將number視為string,或缺少可選欄位。這些問題通常發生在團隊在多個地方定義相同的型別時,導致重複和偏差。
程式碼生成透過直接從資料庫Schema或查詢定義生成型別來解決這個問題。這為你提供了一個單一的真理來源,在你的技術棧中保持同步。
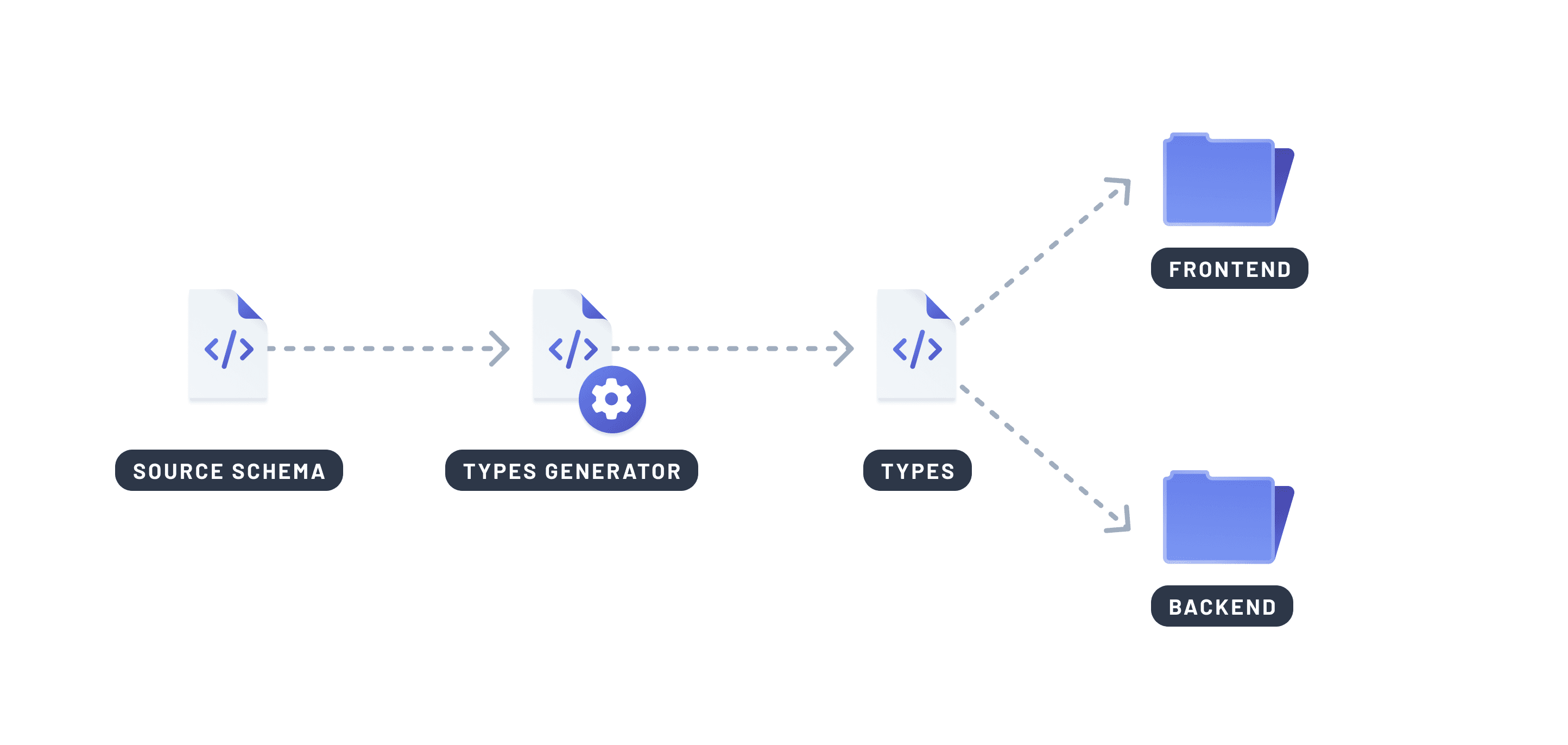
為什麼它很重要
- 避免後端和前端之間手動複製型別
- 防止由型別不匹配或過時契約引起的錯誤
- 在編譯時而非執行時強制執行正確性
- 透過更好的IDE支援和自動補全,使重構更安全
幫助實現此目的的工具示例:Prisma ORM (TypeScript), SQLC (Go), SeaORM (Rust), Pydantic (Python)
當你的應用程式層共享相同的型別定義時,你可以減少錯誤,提高開發者信心,並以更少的意外更快地釋出。
讓AI發現顯而易見(和不那麼顯而易見)的問題
現代AI工具幫助團隊在不犧牲質量的情況下更快地行動。透過將大型語言模型(LLMs)整合到你的開發工作流程中,你可以自動化繁瑣的任務,捕捉細微的問題,並專注於解決真正的問題。
使用LLM驅動的助手來:
- 發現潛在不安全或破壞性的Schema變更
- 總結拉取請求差異以便更快地審查
- 生成測試資料、邊界情況和種子場景
- 直接在拉取請求中推薦改進或標記風險
幫助實現此目的的工具示例:
Windsurf, CodiumAI, Sweep.dev (schema & PR review), GitHub Copilot, Cursor (inline coding help), OpenDevin (backend automation)。
這是Laravel生態系統中的一個例子,名為Enlightn,一個掃描你的應用程式並提供效能、安全等方面的可行建議的工具。
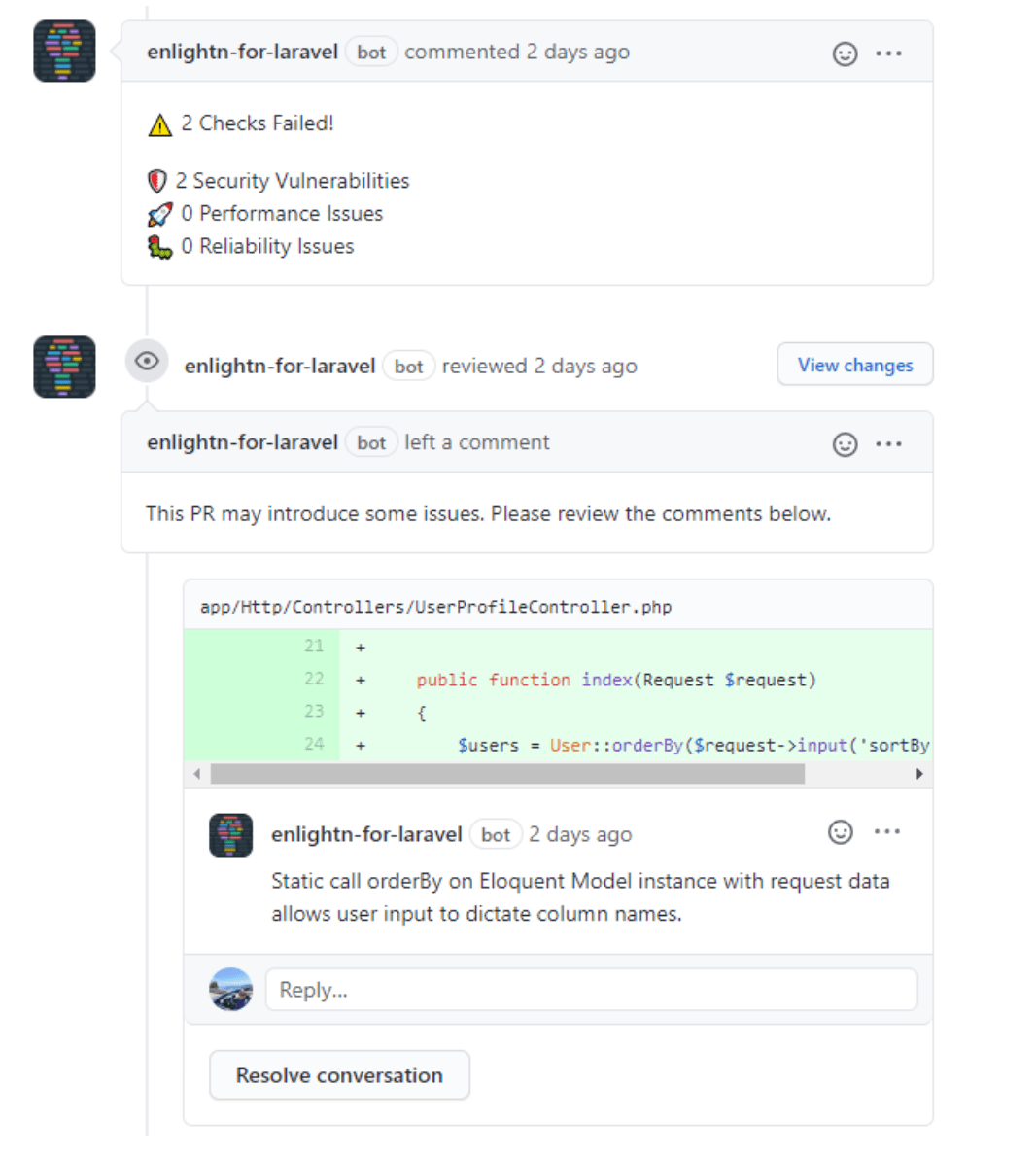
AI不僅僅是為了速度——它是你的第二雙眼睛。明智地使用它,可以幫助你編寫更安全的程式碼,減少審查疲勞,並分擔日常任務,讓你能夠專注於大局。
最佳化團隊速度,而非查詢完美
精心調優的查詢固然有價值,但可靠且一致的交付能力更為重要。優先選擇那些能夠幫助整個團隊更快行動而不犧牲穩定性的工作流程。
專注於以下過程:
- 鼓勵安全的預設設定和合理的約定
- 使新開發者的入職過程變得簡單
- 透過工具和CI及早發現問題
- 平衡效能與程式碼清晰度和可維護性
以速度為重點的實踐示例:
使用帶有防護措施的ORM、程式碼檢查工具和格式化工具、型別安全的API,以及用於查詢迴歸的CI檢查。
快速的團隊交付的價值高於完美調優的查詢;最佳化那些能隨團隊擴充套件而非僅僅資料庫擴充套件的工作流程。
TLDR:構建工作流程,而非混亂
你已經讀到這裡了——太棒了!這裡有一個快速回顧,幫助你鞏固所學。將此表格視為一個診斷和完善當前設定的透鏡,而非一份核對清單。大多數規模化資料挑戰更多地關乎清晰度和一致性,而非技術本身。
一個好的資料工作流程是你的團隊理解、信任並能夠改進的。這才是可擴充套件的。選擇規範和清晰。當每個人都瞭解工作方式時,團隊就能更快地協同前進。
加入對話,塑造更好的工作流程
如果這幫助了你,我們很樂意聽到你的反饋。在X上標記我們並分享你正在構建的內容。或者加入我們的Discord,如果你想聊天、解決問題,或者深入探討資料庫和效能。
我們還定期在YouTube上釋出影片深度解析。如果你喜歡這類內容,請點選訂閱。更多示例、更多效能技巧,或許還有一些驚喜釋出。我們會在那裡見到你。
不要錯過下一篇文章!
訂閱Prisma時事通訊